转眼间进入 Moka 已经快两年了,这么长时间来其实学到了很多,也做了不少优化方面的事情,想想已经很久没认真写博客了,就用这篇文章来记录一下吧。
导读
国际化增量编译 - 初入 Moka
进公司的第一次启动项目,就给我留下了深刻的印(yīn)象(yǐng)。当时的文档里写到,在运行 npm run dev 之前要先运行以下两行命令:
### 国际化
npm run lingui:extract # 从文件内提取翻译内容
npm run lingui:compile # 将需要翻译的内容编译为 js 文件这是我们的国际化步骤,因为之前没有接触过这方面,所以这次操作也给我留下了国际化的初印象:慢如 🦥。

第一行命令跑了足足三分钟,并在终端里依次打印出了项目的所有文件,我当时就在想,以后我每次改动代码,都要这样等么?(很好,摸鱼的时间又增加了
其实大家对这个耗时的操作都积怨已久,因为每次部署也都需要等待这么一步,严重拖慢了我们的部署速度。三分钟对于一个人来说不算多,但是我们团队有二十个人,按每人每天平均部署三次来说,每次部署多花三分钟,每年就浪费掉了 800 个小时,是我塞尔达游玩时长的 1.5 倍了!
仔细分析一下,主要原因有两点:
lingui:extract会囊括当前项目的所有文件,而不只是编译到的文件,或者更新的文件extract步骤需要经过babel解析和遍历
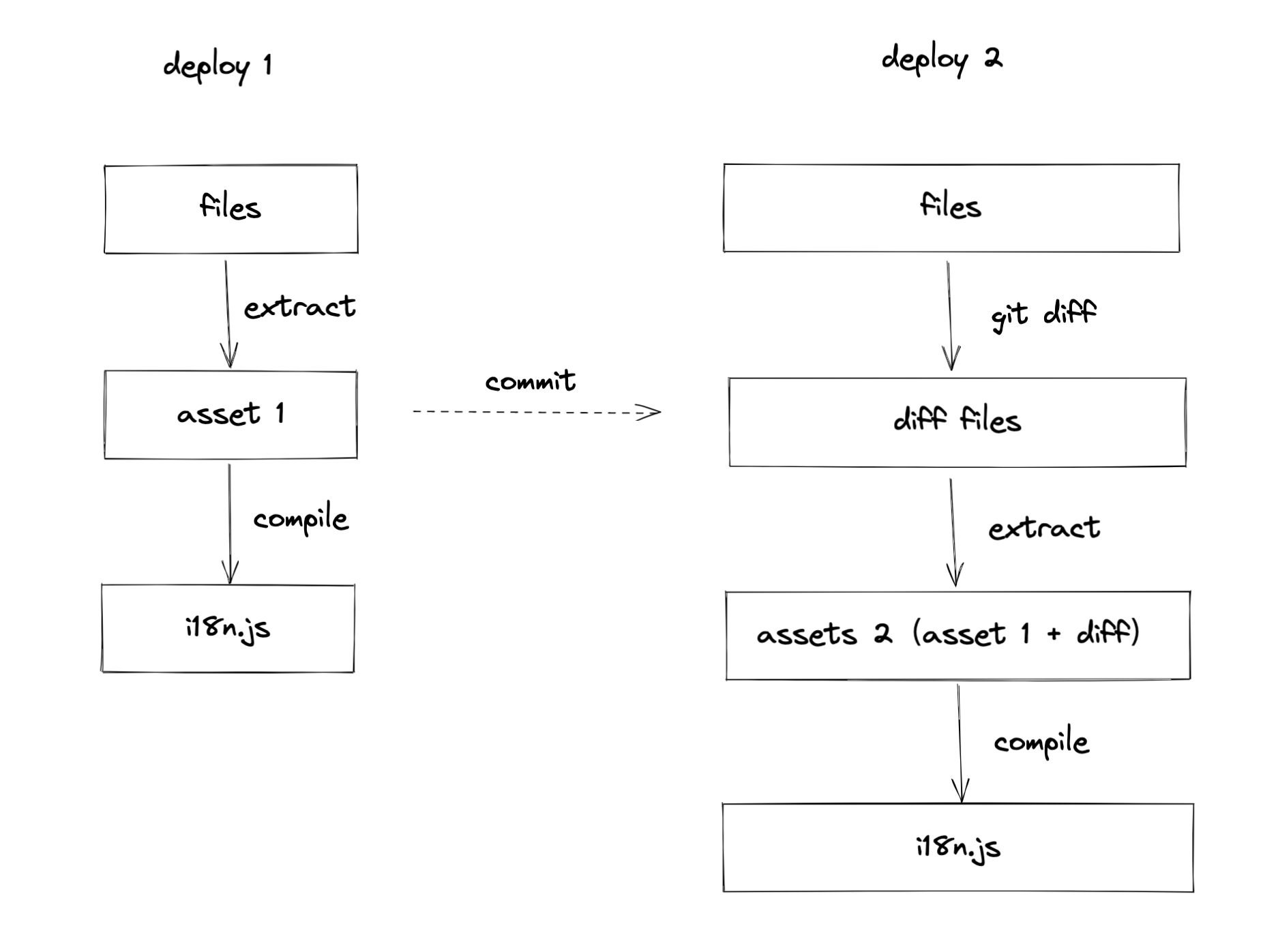
先从第一点的文件数量入手,想到的优化思路是增量编译,如下图:
解释
每一次部署的
extract步骤产生的 assets 会留在部署缓存中,下一次部署时,通过git diff拿到更新的文件列表,通过对这些文件进行extract,再结合之前缓存的 assets,就可以产生新的 assets,最后再通过compile步骤把新的内容编译为 i18n.js,由项目引用。
这样的话每次部署需要 extract 的文件数量就会大大减少,极端情况可能会从数千个减少到个位数,从而提升我们的部署速度。
当时本地测试没问题,合到了 master,因为这是我进公司以来做的第一个大型工程优化,想到能为大家省下那么多时间,还很开心。但是集成测试的第一天,我就被群里各种国际化失效的消息轰炸了,Jira 也顿时从一页变成了多页。
在一个问题无限接近被解决的时候,我们总会过度乐观而因此有意或无意地忽略了一些可能导致其它问题的变量。
在这个问题上我就犯了这个错误:我们是一个多人协作的团队,且拥有多套测试环境,各个环境部署的代码有参差是再常见不过的一个情况。增量编译优化的基础是保留上一次构建的 assets,在优化之前的构建流程中,我们会先清理 assets 目录,保证 assets 是干净的,因此我们在优化的时候删除了清理 assets 目录的步骤。
假设先部署存在增量编译优化的分支 A,再部署没有增量编译优化的分支 B,就会导致 A 产生的 assets 被清除,当再次部署 A 的时候,因为找不到上一次的 assets,最终的 i18n.js 里只会存在 diff 的部分,国际化就失效了。
其实出事儿之后,很快就定位到了问题的原因,但是因为当时我还算个新人,这一次优化没搞成不说,把前端和测试都折腾得不轻,也不敢再轻举妄动,就告一段落了。
接入 esbuild
论编译速度,风驰电掣,舍我其谁 —— by INCHMAN
从 2020 年第一次看到 esbuild 起,我就被深深地吸引了,benchmark 上它的表现简直是将其它编译工具按在地上摩擦,而实际尝试后也是如此,我们的一个小项目用的 webpack,之前编译时间需要 8s,替换为 esbuild 之后只需要 350ms,堪称质的飞跃。

但碍于 esbuild 无法直接将代码编译到 es5,对我们一些用低版本浏览器(包括但不限于 IE、客户端内嵌浏览器等等)的客户来说,这是不能接受的,因此调研阶段到此也就暂停了。
大概过了一周,团队 leader 跟我说,他那边出了一个方案:编译阶段使用 webpack,压缩阶段使用 esbuild。速度能提升不少,但是在 Safari 上遇到了 SyntaxError 的问题。正好我有点 go 的基础,就去调查了一下。
先看报错,是这样一段代码:
// SyntaxError: Invalid character '\u00b7'
var b = { 职位列表·现场申请: "Job list · on-site applications"}\u00b7 是 key 中间的那个连字符号,把这段代码拿到我电脑上的 Safari 里试一下,发现并没有问题。遇见这种情况第一先怀疑浏览器版本,跟 leader 对了一下之后,发现他的 Safari 比我低两三个版本,于是又去找了其他同学,确定低版本的 Safari 确实有这个问题。
分析一下这个 SyntaxError,其实不难看出来,这个写法类似于
var b = { q-w: 123 } // ❌我们都知道通过字面量形式定义对象时,如果作为 key 的字符串中存在特殊字符,是需要添加引号的 ⬇️
var b = { 'q-w': 123 } // ✅这里提示 \u00b7 错误,就可以大胆猜测 \u00b7 应该也是一个特殊字符,如果它存在于 key 中,那整个 key 都需要用引号包裹。于是尝试给 职位列表·现场申请 这个 key 加上引号,发现果然好了。
那 esbuild 是根据什么来决定删除 key 上的引号的呢?
此处调查过程省略......
直接上结论:esbuild 判断一段字符串作为对象的 key 时是否可以省略引号依赖了 npm 上的 unicode 包,版本是 13,这个版本很高,并不能兼容好低版本浏览器。
经过多次尝试,我们将 esbuild 使用的 unicode 包降级到了 5.0 版本,成功地给 \u00b7 加上了引号,经过测试其它功能也都正常。
完成了这个优化后,我们的构建时间又减少了 3-5 分钟,不得不说,新时代的工具就是好用。

想了解这块儿具体细节的童鞋可以转:https://github.com/evanw/esbuild/blob/v0.9.2/scripts/gen-unicode-table.js。目前 esbuild 最新版本已经将 unicode 版本降级到了 3.0,并且加入了更多处理逻辑
不出意外的话肯定有意外
当然使用 esbuild 的过程也不是一帆风顺的,我们遇到过两次问题,分别是
但总的来说,问题不大,而且 esbuild 的 issue 修复速度很快。这里顺便介绍一下 esbuild 作者,Evan Wallace,原 Figma CTO,是一位坚定的 web 新技术践行者与推广者。
推动团队
个人的成长固然重要,但是在一个团队中,所有人都能得到成长才更能促进团队的发展。21 年下半年我们做完项目拆分之后,项目结构简单了许多,因此也产生了很多优化的想法。
注:这部分我的角色主要是提出思路,具体工作是由各位团队成员完成的。
react-dev-inspector
项目地址:https://github.com/zthxxx/react-dev-inspector
这是一个在进行 react 组件开发的时候,可以帮助你从浏览器直接跳转到 IDE 中的插件。
在我们接入的时候,它只提供了 webpack 的 loader,所以我们项目里使用的形式是:
{
test: /\.jsx?$/,
use: [
{
loader: 'babel-loader'
},
{
loader: 'react-dev-inspector/plugins/webpack/inspector-loader'
}
]
}一眼看上去没什么问题,但是仔细想一下,每一次 loader 都会经过 AST 解析,而 react-dev-inspctor 的 loader 内部调用了 babel,也就是说上面的配置中其实经历了两次 babel 解析。
最新版的 react-dev-inspector 1.7.1 提供了 babel 的 plugin,于是我们做了一次升级,将配置修改成了:
{
test: /\.jsx?$/,
use: [
{
loader: 'babel-loader',
options: {
plugins: [
/* ... */
require('react-dev-inspector/plugins/babel')
]
}
}
]
}这样就减少了一次 babel 解析的时间。虽然这次优化的提升有限,但是我们更加了解 loader 的机制了。
ps:这个插件虽然很方便,但是对我来说貌似没什么卵用......
重复包删除
我们的主项目已经开发 6 年了,git 历史甚至比仓库本身还大。在这 6 年的不断发展过程中,不少同学都添加过一些 npm 包,但在添加的时候并没有注意项目中是否已经存在类似的 npm 包,被我们发现的就有:
- mathjs vs decimal.js
- qs vs querystring
第一对是数学库,用来处理一些涉及金额计算场景,最经典的问题就是 0.1 + 0.2 ≠ 0.3;第二对是解析和处理链接里携带的参数的库。
上面的这两对库,功能基本类似,因此可以分别统一成一个,经过实地考察之后,我们分别保留了在使用量和体积上更占优势的 decimal.js 和 qs。
骨架屏优化
作为一款紧跟前端时代潮流的 Saas 应用,我们在 21 年接入了骨架屏,作为提(wei)升(zhuang)我们加载速度的一大利器。
在接入的时候,为了方便直接修改颜色或尺寸进行调试,我们采用了 JSX 的形式:
const skeleton = <svg
width="1030px"
height="575px"
viewBox="0 0 1030 575"
version="1.1"
xmlns="http://www.w3.org/2000/svg"
xmlnsXlink="http://www.w3.org/1999/xlink"
>
{/* ... */}
</svg>经过编译后,skeleton 会以 react 组件的形式存在于代码中
const comp = React.createElement("svg", {
width: "1030px",
height: "575px",
viewBox: "0 0 1030 575",
version: "1.1",
xmlns: "http://www.w3.org/2000/svg",
xmlnsXlink: "http://www.w3.org/1999/xlink"
}, /* ... */);这种形式的问题有两点:
- 编译后代码体积增加
- 在将 skeleton 渲染到页面上的时候,会有 react 运行时的消耗
骨架屏上线之后,其实已经调试完成,这个时候已经不需要再做修改,因此我们将变量形式定义的 svg 提取成了 svg 文件,引入形式修改为 ⬇️
import Skeleton from './skeleton.svg'这样 svg 会以 base64 的形式被内联到 js 文件中,一方面减少了资源体积,另一方面也杜绝了运行时消耗。
国际化资源压缩
这个优化其实是我最 respect 的博哥通过观察国际化资源得出的一个方案。lingui 产出的 i18n 资源分为两部分,中文和英文,类似下面的形式:
// zh_cn_message.js
export default {
测试: '测试',
nav.column: 'xxx'
}
// en_us_message.js
export default {
测试: 'test',
放寒假: '',
}如果项目里有使用到 i18n.translate,在 webpack 进行代码编译的时候,其实会被 babel 内部的 lingui 插件处理成新的形式:
// 处理之前
i18n.translate`测试`
// 处理之后,代码仅作演示,不代表真实情况
i18n.getValueFromMessages('测试', zh_cn_messages)而 getValueFromMessages 的实现做了 fallback 处理,如果 zh_cn_messages 内找不到 key 为 测试的 value,就会 fallback 回 测试。在用户当前系统为中文的情况下,测试 的 fallback 与本身相同,因此我们就可以通过删除 测试 这个 key 来压缩 zh_cn_messages 的体积。
这个优化简单改动了一下 lingui 步骤。经测试,优化之前的 i18n 资源体积在 1.8m 左右,优化后降到了 0.9m,优化掉了 50%,大大减少了我们首屏加载的资源体积。
bonus
除此之外,我们还将 i18n 资源的线上引入形式从原来的 import zhCnMessage from './zh_cn_messages.js' 的形式替换成了 <script src="./zh_cn_messages.js"></script> 标签加载,这样可以利用并行请求为页面加载提速,同时这个修改也为我们下面的国际化步骤精简做了铺垫。
国际化步骤精简
上次国际化优化失败之后,又过了一年,其实我心里一直惦记着这个,隐隐约约觉得优化的空间还很大。
这一年不只是我成长了,我们的部署流程也有了很大的改变,从 Jenkins 迁移到了 Gitlab CI + 容器化,相比 Jenkins,容器化的方式更方便、易集成,也更容易理解。
之前的优化中,我们是从原因的第一点——文件数量——入手,容器化迁移之后,缓存变得难以维护,因此这一优化方案也就失去了探索的可行性。但是我们还有第二点,babel,无论是替换 babel 还是利用 babel 本身,只要能够加快 extract 步骤的处理,我们就可以提升编译速度。
第一次尝试
在上次修改 i18n 资源引入形式的时候,我们其实做到了另一点:项目和 lingui 的编译分离。也就是说我们可以在项目编译的同时做 lingui:extract 步骤,这就有了我们的第一个方案,通过并行调用加速编译:
parallel([
webpack(config), // 编译
exec('npm run lingui:extract'), // lingui 步骤
])我们对这个方案寄予了厚望,但是上线之后发现速度提升并不明显,只快了大概十几秒,怀疑是 CI 资源不足导致并行效率低,跟运维沟通了一次,他们那边不太好解决,因此第一次尝试以失败告终。
重新审视构建流程
我们的 babelrc 配置如下:
{
"presets": [
"@babel/preset-env",
"@lingui/babel-preset-js",
"@babel/preset-react",
"@lingui/babel-preset-react"
],
"plugins": [
"@lingui/babel-plugin-extract-messages",
"@babel/plugin-syntax-dynamic-import",
// ...
],
// ...
}据此我们可以推断出 lingui:extract 内部调用了 babel 解析,配合这些 preset 和 plugin 提取项目中的国际化文本。但仔细想想,babel 解析在 webpack 编译调用 babel-loader 时不也同样存在么?画一下图
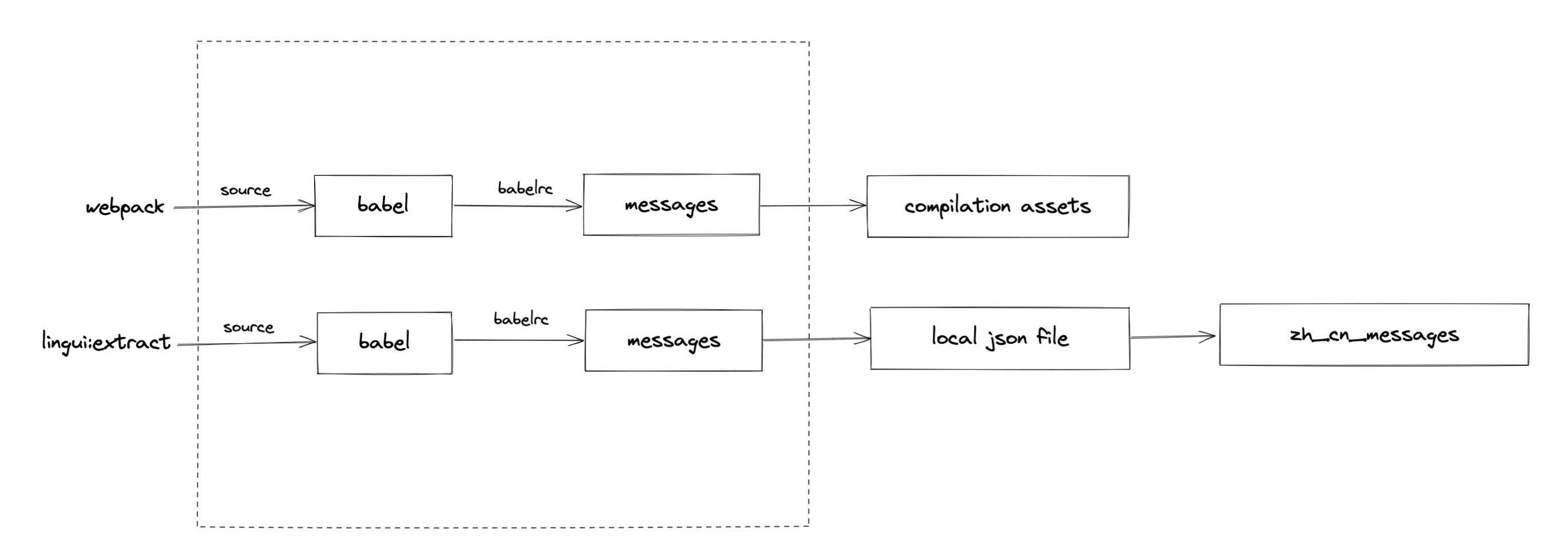
有了图就能看得很清晰:在虚线框内,lingui:extract 和 webpack 编译是重叠的,也就是说如果 lingui:extract 如果没有太多特殊处理的话,这部分是可以被复用的。
于是开始翻 lingui 源码,很快就证实了这个结论,lingui:extract 只是在 babel 编译完成之后,将所有文件提取出的单个 json 文件聚合成了一个大 json 文件,而这些 json 文件,在经过 babel-loader 的时候也会生成,只不过算是副作用,并不会使用。
这个时候就不得不再提一下上面修改 i18n 资源线上引入形式的优化,这个改动提供了我们在 webpack 编译完成之后再去处理国际化资源的能力。
到这个阶段优化方案就浮出水面了:先通过 webpack 编译项目资源,然后利用 babel-loader 产生的 json 文件进行自定义 extract,完全替换掉 lingui:extract 步骤。
优化前 lingui:extract 步骤占了三分钟,而自定义的 extract 耗费的时间在秒级,基本可以忽略,优化后相当于项目构建时间直接减少三分钟。

终于,lingui 优化彻底告一段落,心满意足 (¯︶¯)
插曲
虽然每年节省了 800 个小时,但荒野之息 2 跳票了!(╯‵□′)╯︵┻━┻
图片引用方案优化
其实在更早之前,我们的项目是一个前后端共存的 monorepo,文件夹结构类似:
src
├── main-app // 前端项目
└── server
└── public
└── images // 图片资源在打包完成后,src/server/public 下会多出 javascripts 和 stylesheets 文件夹,服务端会将整个 public 目录作为静态文件目录,通过 node 提供出去,所以前端在访问 /javascripts/xxx.js 时,就可以访问到对应目录的资源。
在以前那个构建还很混乱的时代,前端出现了通过 /images/xxx.png 访问图片的情况,这种写法会在 webpack 打包之后保留原状,并且如果 img 标签中出现这种写法,页面在访问时会在图片路径前面挂上页面域名,而不是 webpack_public_path,也就是我们的 cdn 域名进行访问。
<!--
页面域名 main.com
最终发起的 http 请求是 https://main.com/images/xxx.png
-->
<img src="/images/xxx.png" />
<!--
页面域名 main.com,webpack 的 publicPath 配置 cdn.com/images/
最终发起的 http 请求是 https://cdn.com/images/xxx.png
-->
import xxx from '../images/xxx.png'
<img src={xxx} />但是在前端拆分项目的时候,images 标签的写法并没有修改,所以拆分后的项目访问的仍是原始项目的资源,这就导致了一个尴尬的局面:在增加图片时,我们需要在拆分后的新项目(开发环境)和原始项目(测试、生产环境)中同时增加,而不能只增加一侧。
随着业务的发展,我们从一个端,拆到了九个端,这九个端中,除了两个新项目外,剩下七个项目的图片都需要在原始项目中存在,抛开图片体积不说,数量和文件夹的结构也足够我们梳理了,并且每一个新人第一次添加图片的时候,都会踩到这个坑,甚至有些老人还会忘记这个问题,导致排查了半天最后只能敲桌子的情况。
import 化
这个优化的思路很简单,主要的痛点是工作量。如果一个一个手动修改,在一个项目迁移完之后,余下几个项目还需要同等的工作量,因此我写了一个脚本用来辅助处理迁移过程。这里贴一下大概的思路:
/**
* 重构项目中的图片使用方式
* 1. js/ts/tsx 文件修改为 import 形式
* 2. css/styl 文件内里 url 修改为从 target folder 下引入
*/
const fs = require('fs');
const path = require('path');
const DEFAULT_OPTIONS = {
root: 'src',
source: 'xxx',
target: 'xxx',
};
const rootFolder = path.resolve(DEFAULT_OPTIONS.root);
const sourceFolder = path.resolve(DEFAULT_OPTIONS.source);
const targetFolder = path.resolve(DEFAULT_OPTIONS.target);
function lookUpFiles(folder = '') {
/** 递归查找文件 */
}
function moveFileToStatic(match) {
/*** 移动文件 */
}
/**
* 重构 js/ts/tsx 文件里图片的引入形式,主要操作:
* 1. 在 import 中添加图片的引入
* 2. 修改属性或者字面量里的引入为变量,eg.
* | const src = '/images/xxx.png' -> const src = xxxPng;
* | src="/images/xxx.png" -> src={xxxPng}
* 3. 移动文件
*
* @param {string} file 文件路径
*/
async function refactorJs(file) {
const content = fs.readFileSync(path.resolve(file), 'utf-8');
const lines = content.split('\n');
const newImports = new Set();
const newLines = [];
lines.forEach((line, index) => {
/** 替换引用形式 */
const relative = path.relative(path.dirname(file), targetFolder);
const matchHandler = (match) => {
const oldPath = match.replace(/\"|\'/g, '');
const fileName = toCamelCase(path.basename(oldPath));
const newImport = `import ${fileName} from '${relative}${toCamelCaseForPath(oldPath)}';`;
// 用 index 处理单行内存在多处匹配的情况
newLines[index] = newLines[index].replace(match, `{${fileName}}`);
moveFileToStatic(oldPath);
};
const matches = line.match(/'(\/images\/[^']+)'/g);
if (matches) {
matches.forEach((match) => matchHandler(match));
}
});
fs.writeFileSync(file, [...newImports, ...newLines].join('\n'));
}
/** 重构 css 文件里图片的引用形式 */
async function refactorCss(file) {
/** 同上 */
}
async function main() {
const files = lookUpFiles(rootFolder);
if (!fs.existsSync(targetFolder)) {
fs.mkdirSync(targetFolder, { recursive: true });
}
for (const file of files) {
if (/\.(js|ts|tsx)$/.test(file)) {
refactorJs(file);
}
if (/\.(css|styl)$/.test(file)) {
refactorCss(file);
}
}
}
main();这次优化算是清理了一波历史债务,优化之后,我们就将新项目和老项目彻底分开了,老项目是否持续优化要视情况而定,而新项目则进入了现代化工程体系建设的时代!
beyond
上面这些优化做完之后,我们的项目形态、开发效率和性能较之前已经有了很大的提升,但优化并不是一个目标,而是一个持续的过程,随着业务规模的增长、团队的扩大和前端的发展,一定会出现更多的优化方案和手段,帮助我们更好地进行开发和维护。
比如团队最近在做全面 lint 和 unit test 接入的事情,这里就不展开赘述了,市面上有现成的方案,有兴趣的可以自己搜索。
特别致谢
感谢团队里的各位成员在上述优化中做出的贡献,包括但不限于直接参与、支持/了解、提出思路和问题,同时感谢各位直接参与的同学在各个优化中付出的辛劳和 💦。
